हालांकि, यह अभी भी अपने प्रतिद्वंद्वियों की तुलना में सस्ता है।
दीपसेक के नए चैटबॉट ने मुझे एक पेचीदा परिचय के साथ बधाई दी:
नमस्ते, मैं बनाया गया था ताकि आप कुछ भी पूछ सकें और एक उत्तर प्राप्त कर सकें जो आपको आश्चर्यचकित भी कर सकता है।
आज, डीपसेक की कृत्रिम बुद्धिमत्ता बाजार में एक दुर्जेय खिलाड़ी के रूप में उभरी है, यहां तक कि एनवीडिया के सबसे महत्वपूर्ण स्टॉक मूल्य में से एक का कारण भी बन गया है।
 चित्र: ensigame.com
चित्र: ensigame.com
इस मॉडल को अलग करने के लिए इसकी अभिनव वास्तुकला और प्रशिक्षण के तरीके हैं। दीपसेक कई अत्याधुनिक प्रौद्योगिकियों को नियोजित करता है:
मल्टी-टोकन भविष्यवाणी (एमटीपी): एक समय में एक शब्द की भविष्यवाणी करने के बजाय, मॉडल एक वाक्य के विभिन्न भागों का विश्लेषण करके एक साथ कई शब्दों का पूर्वानुमान लगाता है। यह दृष्टिकोण मॉडल की सटीकता और दक्षता दोनों को बढ़ाता है।
विशेषज्ञों का मिश्रण (एमओई): यह आर्किटेक्चर इनपुट डेटा को संसाधित करने के लिए विभिन्न तंत्रिका नेटवर्क का उपयोग करता है। प्रौद्योगिकी एआई प्रशिक्षण को तेज करती है और प्रदर्शन में सुधार करती है। दीपसेक V3 में, 256 तंत्रिका नेटवर्क का उपयोग किया जाता है, जिसमें प्रत्येक टोकन प्रसंस्करण कार्य के लिए आठ सक्रिय होते हैं।
मल्टी-हेड लेटेंट ध्यान (एमएलए): यह तंत्र एक वाक्य के सबसे महत्वपूर्ण भागों पर ध्यान केंद्रित करने में मदद करता है। MLA केवल एक बार के बजाय बार -बार पाठ टुकड़ों से महत्वपूर्ण विवरण निकालता है, जिससे लापता महत्वपूर्ण जानकारी लापता होने की संभावना कम होती है। यह एआई को इनपुट डेटा में महत्वपूर्ण बारीकियों को अधिक प्रभावी ढंग से पकड़ने में सक्षम बनाता है।
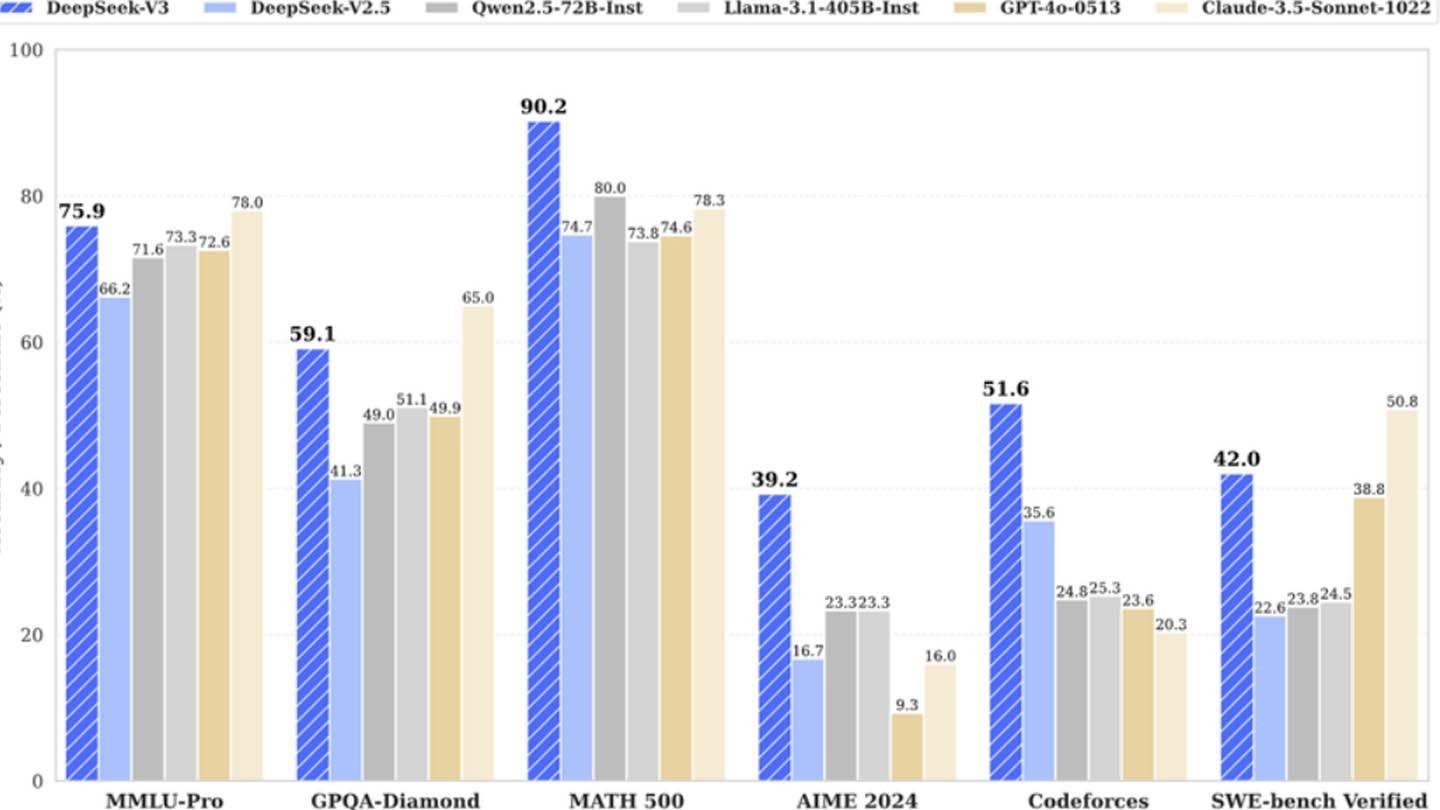
प्रमुख चीनी स्टार्टअप दीपसेक ने दावा किया है कि उन्होंने कम से कम लागत पर एक प्रतिस्पर्धी एआई मॉडल विकसित किया है, जिसमें कहा गया है कि उन्होंने शक्तिशाली न्यूरल नेटवर्क डीपसेक वी 3 को प्रशिक्षित करने पर केवल $ 6 मिलियन खर्च किए और सिर्फ 2048 ग्राफिक्स प्रोसेसर का उपयोग किया।
 चित्र: ensigame.com
चित्र: ensigame.com
हालांकि, सेमियनलिसिस के विश्लेषकों ने खुलासा किया है कि डीपसेक एक बड़े कम्प्यूटेशनल बुनियादी ढांचे का संचालन करता है जिसमें लगभग 50,000 एनवीडिया हॉपर जीपीयू शामिल हैं। इसमें 10,000 H800 इकाइयाँ, 10,000 अधिक उन्नत H100, और H20 GPU के अतिरिक्त बैच शामिल हैं। इन संसाधनों को कई डेटा केंद्रों में वितरित किया जाता है और एआई प्रशिक्षण, अनुसंधान और वित्तीय मॉडलिंग के लिए उपयोग किया जाता है।
सर्वर में कंपनी का कुल निवेश लगभग 1.6 बिलियन डॉलर है, जिसमें परिचालन खर्च $ 944 मिलियन है।
दीपसेक चीनी हेज फंड हाई-फ्लायर की एक सहायक कंपनी है, जो 2023 में एआई प्रौद्योगिकियों पर केंद्रित एक अलग डिवीजन के रूप में स्टार्टअप को बंद कर देती है। क्लाउड प्रदाताओं से कम्प्यूटिंग पावर को किराए पर लेने वाले अधिकांश स्टार्टअप्स के विपरीत, डीपसेक अपने स्वयं के डेटा केंद्रों का मालिक है, यह एआई मॉडल अनुकूलन पर पूर्ण नियंत्रण देता है और नवाचारों के तेजी से कार्यान्वयन को सक्षम करता है। कंपनी स्व-वित्त पोषित बनी हुई है, जो इसके लचीलेपन और निर्णय लेने की गति को सकारात्मक रूप से प्रभावित करती है।
 चित्र: ensigame.com
चित्र: ensigame.com
इसके अलावा, दीपसेक के कुछ शोधकर्ता सालाना $ 1.3 मिलियन से अधिक कमाते हैं, प्रमुख चीनी विश्वविद्यालयों से शीर्ष प्रतिभा को आकर्षित करते हैं (कंपनी विदेशी विशेषज्ञों को काम पर नहीं रखती है)।
यहां तक कि इन कारकों के साथ, दीपसेक के हालिया $ 6 मिलियन के लिए अपने नवीनतम मॉडल को प्रशिक्षित करने का दावा अवास्तविक लगता है। यह आंकड़ा केवल पूर्व-प्रशिक्षण के दौरान GPU उपयोग की लागत को संदर्भित करता है और अनुसंधान व्यय, मॉडल शोधन, डेटा प्रसंस्करण, या समग्र बुनियादी ढांचे की लागत के लिए जिम्मेदार नहीं है।
अपनी स्थापना के बाद से, दीपसेक ने एआई विकास में $ 500 मिलियन से अधिक का निवेश किया है। हालांकि, बड़ी कंपनियों के विपरीत नौकरशाही से बोझिल, डीपसेक की कॉम्पैक्ट संरचना इसे सक्रिय रूप से और प्रभावी रूप से एआई नवाचारों को लागू करने की अनुमति देती है।
 चित्र: ensigame.com
चित्र: ensigame.com
दीपसेक का उदाहरण दर्शाता है कि एक अच्छी तरह से वित्त पोषित स्वतंत्र एआई कंपनी उद्योग के नेताओं के साथ प्रतिस्पर्धा कर सकती है। फिर भी, विशेषज्ञ इस बात पर जोर देते हैं कि कंपनी की सफलता काफी हद तक निवेश, तकनीकी सफलताओं और एक मजबूत टीम में अरबों के कारण है, जबकि एआई मॉडल विकसित करने के लिए "क्रांतिकारी बजट" के बारे में दावे कुछ हद तक अतिरंजित हैं।
फिर भी, प्रतियोगियों की लागत काफी अधिक है। उदाहरण के लिए, मॉडल प्रशिक्षण की लागत की तुलना करें: दीपसेक ने R1 पर $ 5 मिलियन खर्च किए, जबकि CHATGPT4O की लागत $ 100 मिलियन है।














